![[DB] 1. 데이터 베이스 시스템(TIL_230904)](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FlmhZc%2FbtssUOSruw2%2FELgLdKYuUYo6iEepQXY6o0%2Fimg.png)
해당 블로그의 글을 보고 요약, 정리한 글입니다.
해당 블로그에 좋은글이 많으니 참고해보시면 좋을 것 같습니다
1. 데이터베이스와 데이터베이스 시스템
[데이터, 정보, 지식]
- 데이터: 관찰의; 결과로 나타난 정량적 혹은 정성적인 실제 값
- 정보: 데이터에 의미 부여한 것
- 지식: 사물에 대한 이해
[데이터 베이스]
- 데이터 베이스: 조직에 필요한 정보를 얻기 위해 논리적으로 연관된 데이터를 모아 구조적으로 통합해 놓은 것
- 데이터 베이스 시스템은 검색(select)와 변경(insert, delete 등) 작업을 주로 수행한다
- 변경이란 시간에 따라 변한느 데이터 값을 데이터베이스에 반영하기 위해 수행하는 삽입, 삭제, 수정 등을 말함
데이터 베이스는 우리에게 정보들을 구조적으로 모아둔 것
[데이터 베이스의 개념]
- 통합된 데이터: 데이터를 통합하는 개념, 데이터의 중복을 최소화하여 중복으로 인한 데이터 불일치 제거
- 저장된 데이터: 문서로 보관된 데이터가 아니라 컴퓨터 저장장치에 저장된 데이터
- 운영 데이터: 조직의 목적을 위해 사용되는 데이터, 업무를 위한 검색을 목적으로 저장됨
- 공용 데이터: 한 사람 또는 한 업무를 위해 사용되는 데이터가 아니라 공동으로 사용되는 데이터
[데이터 베이스 특징]
- 실시간 접근성
- 계속적인 변화
- 동시 공유 - 여러 사용자에게 동시 공유
- 내용에 따른 참조 - 물리적 위치가 아닌 값에 따라 참조됨
[데이터베이스 시스템의 구성]
- DBMS : 사용자와 데이터베이스를 연결시켜주는 소프트웨어
- 데이터베이스: 데이터를 모아둔 토대
- 데이터 모델: 데이터가 저장되는 기법에 관한 내용
데이터들은 데이터베이스에 저장되어있습니다. 그런데 데이터를 어떻게 저장할 것인지 의미하는 것이 데이터 모델이고, 개발자가 데이터베이스로부터 데이터를 꺼내오기 위해 데이터베이스와 연결시켜주는 소프트웨어가 DBMS이다.

2. 데이터베이스 시스템의 발전
[1. 파일시스템]
- 데이터를 파일 단위로 파일 서버에 저장
- 각 컴퓨터는 LAN을 통해 파일 서버에 연경되어있고, 파일 서버에 저장된 데이터를 사용하기 위해 각 컴퓨터의 응용 프로그램에서 열기 닫기를 요청했다
- 각 프로그램이 독립적으로 파일을 다루기 때 문에 데이터가 중복 저장될 가능성이 있다
- 동시에 파일을 다루기 때문에 데이터의 일관성이 훼손될 수 있다
- 여러개의 클라이언트가 파일에 접근하는 방식이기 때문에 데이터의 중복 저장과 일관성 훼손이라는 단점을 갖게 된다

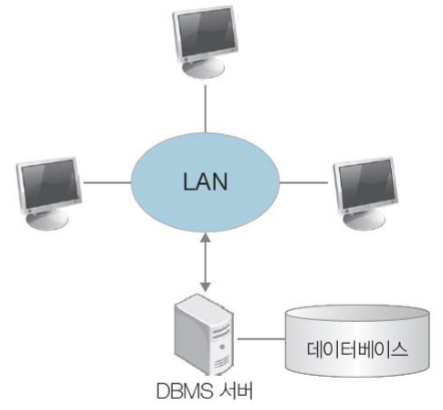
[2. 데이터베이스 시스템]
- DBMS를 도입하여 데이터를 통합 관리하는 시스템
- DBMS가 설치되어 데이터를 가진 쪽을 서버, 데이터를 요청하는 쪽을 클라이언트라고 함
- DBMS 서버가 파일을 다루며 데이터의 일관성 유지, 복구, 동시접근제어 등의 기능을 수행
- 데이터의 중복을 줄이고 데이터를 표준화하며 무결성을 유지한다
- 클라이언트가 데이터베이스에 있는 데이터를 얻기위해 서버로 요청하는데 이때 데이터베이스로의 연결을 위해 사용되는 것이 DBMS 서버
- DBMS서버는 데이터의 일관성유지, 복구, 동시접근제어 등의 기능을 수행
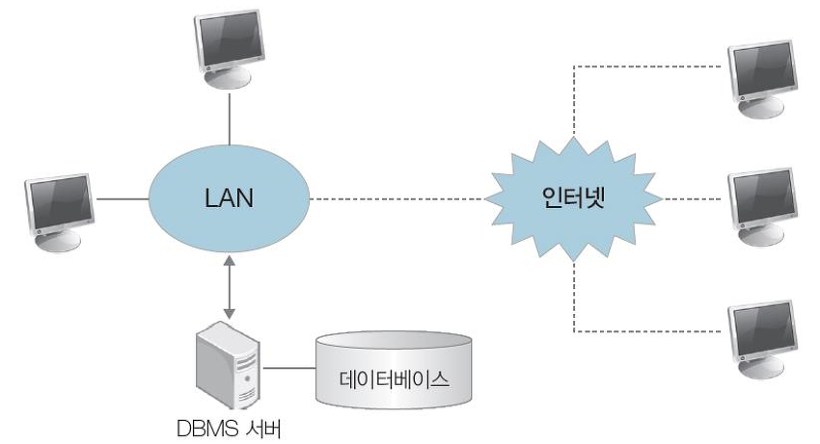
[3. 웹 데이터베이스 시스템]
- 데이터베이스를 웹 브라우저에서 사용할 수 있도록 서비스하는 시스템
- 불특정 다수의 고객을 상대로하는 온라인 상거래나 공공 민원 서비스 등에 사용됨
- 기존 DB는 LAN으로 연결된 컴퓨터만 접근 가능했다면, 웹 DB 시스템은 인터넷을 ㅗㅇ해 LAN으로 연결되어 있지 않은 클라이언트들도 DB로 접근 가능하다는 장점을 가짐
[4. 분산 데이터베이스 시스템]
- 여러 곳에 분산된 DBMS서버를 연결하여 운영하는 시스템
- 대규모 응용 시스템에 사용됨
- 여러개의 서버로 분리하여 서버끼리의 동기화를 유지하며 운영하는 것이 분산 데이터베이스 시스템
[파일 시스템과 DBMS 비교]

[파일 시스템과 비교한 DBMS의 장점]
| 구분 | 파일 시스템 | DBMS |
| 데이터 중복 | 데이터를 파일 단위로 저장하므로 중복 가능 | DBMS를 이용하여 데이터를 공유하기 때문에 중복 가능성 낮음 |
| 데이터 일관성 | 데이터의 중복 저장으로 일관성이 결여됨 | 중복 제거로 데이터의 일관성이 유지됨 |
| 데이터 독립성 | 데이터 정의와 프로그램의 독립성 유지 불가능 | 데이터 정의와 프로그램의 독립성 유지 가능 |
| 관리 기능 | 보통 | 데이터 복구, 보안, 동시성 제어, 데이터 관리 기능 등 수행 |
| 프로그램 개발 생산성 | 나쁨 | 짧은 시간에 큰 프로그램을 개발할 수 있음 |
| 기타 장점 | 보통 | 데이터 무결성 유지, 데이터 표준 준수 용이 |
4. 데이터 베이스 시스템 구성
4종류로 분류되는 데이터베이스 사용자
[일반 사용자]
- 은행의 창구 혹은 관공서의 민원 접수처 등에서 데이터 다루는 업무를 하는 사람
- 프로그래머가 개발한 프로그램을 이용해 데이터베이스에 접근한느 일반인
[응용 프로그래머]
- 일반 사용자가 사용할 수 있도록 프로그램을 만드는 사람
- Java, C, JSP 등의 프로그래밍 언어와 SQL을 사용해 일반 사용자를 위한 UI와 데이터 관리하는 응용로직 개발
[SQL 사용자]
- SQL을 사용하여 업무를 처리하는 IT부서 담당자
- 응용 프로그램으로 구현되어 있지 않은 업무를 SQL을 사용해 처리
- Select, Insert, Delete 등과 같은 쿼리문을 사용해 데이터를 추가하거나 필요한 테이블 추가적으로 생성
[데이터베이스 관리자(DBA)]
- DataBase Administrator로 데이터베이스 운영 조직의 시스템을 총괄하는 사람
- 데이터 설계, 구현, 유지보수의 전 과정을 담당
- 데이터베이스 사용자 통제, 보안, 성능 모니터링, 데이터 전체 파악 및 관리, 데이터 이동 및 복사 등 제반 업무
[전체 데이터베이스 사용자]

[DBMS의 기능]
- 데이터 정의 (Definition) : 데이터의 구조를 정의하고 데이터 구조에 대한 삭제 및 변경 기능 수행
- 데이터 조작 (Manipulation) : 데이터를 조작하는 프로그램이 요청하는 데이터의 삽입, 수정, 삭제 작업 지원
- 데이터 추출 (Retrieval) : 사용자가 조회하는 데이터 혹은 응용 프로그램의 데이터 추출
- 데이터 제어 (Control) : 데이터베이스 사용자를 생성하고 모니터링해 접근을 제어. 백업과 회복, 동시성제어 등 지원
데이터 정의와 데이터 조작이 비슷해 보이지만 정의를 데이터 구조(Table)에 대해서 작업을 하는 것이고 데이터 조작은 Table에 들어있는 데이터에 대해서 작업을 하는 것
[데이터 모델(Data Model)]
- 계층 데이터 모델
- 네트워크 데이터 모델
- 관계 데이터 모델
- 객체 데이터 모델
- 객체-관계 데이터 모델
가장 많이 사용되는 모델은 관계 데이터 모델이다.
관계 데이터 모델은 서로 연관된 데이터들을 테이블로 모아두는 구조인데, 객체지향 프로그래밍 언어와는 맞지 않아서 ORM(Object Relational Mapping)을 사용하는 경우가 많다
*ORM : 객체(Object)와 DB의 테이블을 Mapping시켜 RDB테이블을 객체지향적으로 사용하게 해주는 기술
[관계 데이터 모델]
관계 데이터 모델에서는 아래 그림처럼 소성값을 사용한다
학생이라는 관계에서는 학번과 이름, 그리고 수강하는 강좌번호라는 속성이 필요하고, 강좌라는 관계에서는 강좌번호, 강좌이름에 대한 속성이 필요한데 이때 학생의 강좌번호와 강좌의 강좌번호를 사용하여 두 데이터를 연결시킴

[3단계 데이터베이스 구조]
- 외부 스키마
- 개념 스키마
- 내부 스키마
각각의 스키마에 대해 자세히 살펴보자.

[외부 스키마]
- 일반 사용자나 응요 프로그래머가 접근하는 계층으로 전체 데이터베이스 중 하나의 논리적 부분을 의미
- 여러개의 외부 스키마가 있을 수 있음
- 서브 스키마 라고도 하며, View의 개념
- 겉으로 보이는 DB, Table 형태를 의미
- 사용 주체나 응용에 따라서 바라보는 구조가 다를 수 있다
- 누군가는 Select문을 이용해 조회할 수 있는데 이때 우리가 보게 되는 것을 외부 스키마라고 이해
- 다이어그램처럼 표시되어 있지만 다른 형태로도 데이터 볼 수 있고 그 역시도 외부 스키마라고함
- 외부스키마는 개념 스키마의 부분집합이 된다

[개념 스키마]
전체 데이터베이스의 정의를 의미
통합 조직별로 하나만 존재하며 DBA가 관리함
하나의 데이터베이스에는 하나의 개념 스키마가 존재
우리에게 필요한 데이터만 추출해 보는 외부스키마는 개념 스키마의 부분집합이 될 수 밖에 없다
개념 스키마는 데이터베이스에서 매우 중요한 비중을 차지하기 때문에 하나만 존재하며 이를 DBA가 관리함

[내부 스키마]
- 물리적 저장 장치에 데이터베이스가 실제로 저장되는 방법의 표현
- 내부스키마 역시 하나만 존재
- 인덱스, 데이터 레코드의 배치방법, 데이터 압축 등에 관한 사항이 포함됨
- 실제 구현에 관한 이야기 이 속성이 어떤 형태이며 어느 정도의 크리를 갖는지 등에 관해 기술해둔 스키마 의미

[매핑(Mapping)]
- 외부/개념 매핑
- 개념/내부 매핑
외부/개념 매핑을 사용자의 외부스키마와 개념 스키마 간의 매핑(사상)을 의미하며 외부 스키마의 데이터가 개념 스키마의 어느 부분에 해당되는지 대응 시키는 것이다. 개념/내부 매핑을 개념 스키마의 데이터가 내부 스키마의 물리적 장치 어디에 어떤 방법으로 저장되는지를 대응시키는 것
[논리적 데이터 독립성]
- 외부 스키마와 개념 스키마 사이의 독립성
- 개념스키마가 변경되어도 외부 스키마에는 영향을 미치지 않도록 지원
- 논리적 구조가 변경되어도 응요 프로그램에는 영향이 없도록 하는 개념
- 개념 스키마의 테이블을 생성하거나 변경해도 외부 스키마가 직접 다루는 테이블이 아니면 영향이 없다
카카오톡 친구들 목록을 본다고 가정할 때, 카카오 선물의 빼빼로 가격이 1000원 올랐다해도 직접 다루고 있는 테이블이 아니기 때 무네 영향을 주지 않는다. 이렇게 우리가 보는 외부 스키마와 개념 스키마가 서로 영향을 주지 않게 분리해 놓은 것을 논리적 데이터 독립성이라 한다.
[물리적 데이터 독립성]
- 개념 스키마와 내부 스키마 사이의 독립성
- 저장장치 구조 변경과 같이 내부스키마가 변경되어도 개념 스키마에 영향을 미치지 않도록 지원
- 성능 개선을 위해 물리적 저장 장치를 재구성할 경우 개념 스키마나 외부 스키마에 영향이 없음
- 물리적 독립성은 논리적 독립성보다 구현하기 쉬움
주소의 크기를 VARCHAR(100)에서 VARCHAR(50)으로 바꾼다 가정했을 때 개념ㄴ 스키마에는 영향을 주지 않는데 이를 물리적 데이터 독립성이라 한다.